Different Types of Neural Networks
Part 4
So far, we have only covered one type of neural network: the feedforward neural network (FNN) (otherwise known as a multilayer perceptron (MLP)). But there exist hundreds more "varieties" of networks that we haven't discussed, each of which work in a slightly different way. Over the years, we have developed many different “architectures”, each optimised for solving specific kinds of problems. Here are some of the major types:
▬▬▬▬▬▬
Feedforward Neural Networks (FNNs)
We probably don't need to spend that much time on this section. The last 3 tutorials were dedicated to this type of neural network, but here's a summary:
Feedforward neural networks are the simplest type of neural network. They consist of layers of nodes (neurons) with strictly forward flow: from the input layer, through one or more hidden layers, and to the output layer. Each node takes a weighted sum of its inputs, applies an activation function, and forwards the result to the next layer. Since the connections never disconnect, information flows in just one direction. FNNs are universal function approximators A universal function approximator is a computational model, such as a feedforward neural network, that can learn to compute any continuous function to an arbitrary degree of accuracy, given enough complexity and resources. and are used occasionally for tasks where inputs might map directly to the outputs, such as simple regressionA regression problem involves a machine learning algorithm learning the continuous relationship between independent variables (features) and a dependent variable (output) to predict a numerical value or classification.
Neural Network Diagram (H.Y. using Canva)
▬▬▬▬▬▬
Convolutional Neural Networks (CNNs)
Convolutional neural networks were designed to handle data with a grid-like structure, most commonly images. Instead of connecting every neuron in one layer to every neuron in the next layer, CNNs use convolutional filters (small moving windows) to apply them to the input. These filters locate local features such as edges, textures, or shapes. With every group of several convolutional layers, progressively higher-level features are learned by the network, from simple edges to complex objects. However, CNNs come with additional complexities and more features. For example, we implement pooling layersIn the context of CNNs, pooling is a step where the network reduces the size of its data by summarizing small regions. It usually does this by taking the max or the average, which helps keep the key information while cutting out extra detail. to reduce the spatial size of data by keep things efficient and pull out only the most crucial details. CNNs work well because they can exploit spatial localitySpatial locality means nearby pixels in an image are usually related, so patterns often appear in local regions. and weight sharingWeight sharing is when the same filter (set of weights) is applied across different parts of the input, so the network can detect the same feature no matter where it shows up. This makes the model more efficient and less prone to overfitting. , which makes them excellent at image recognition and similar applications.
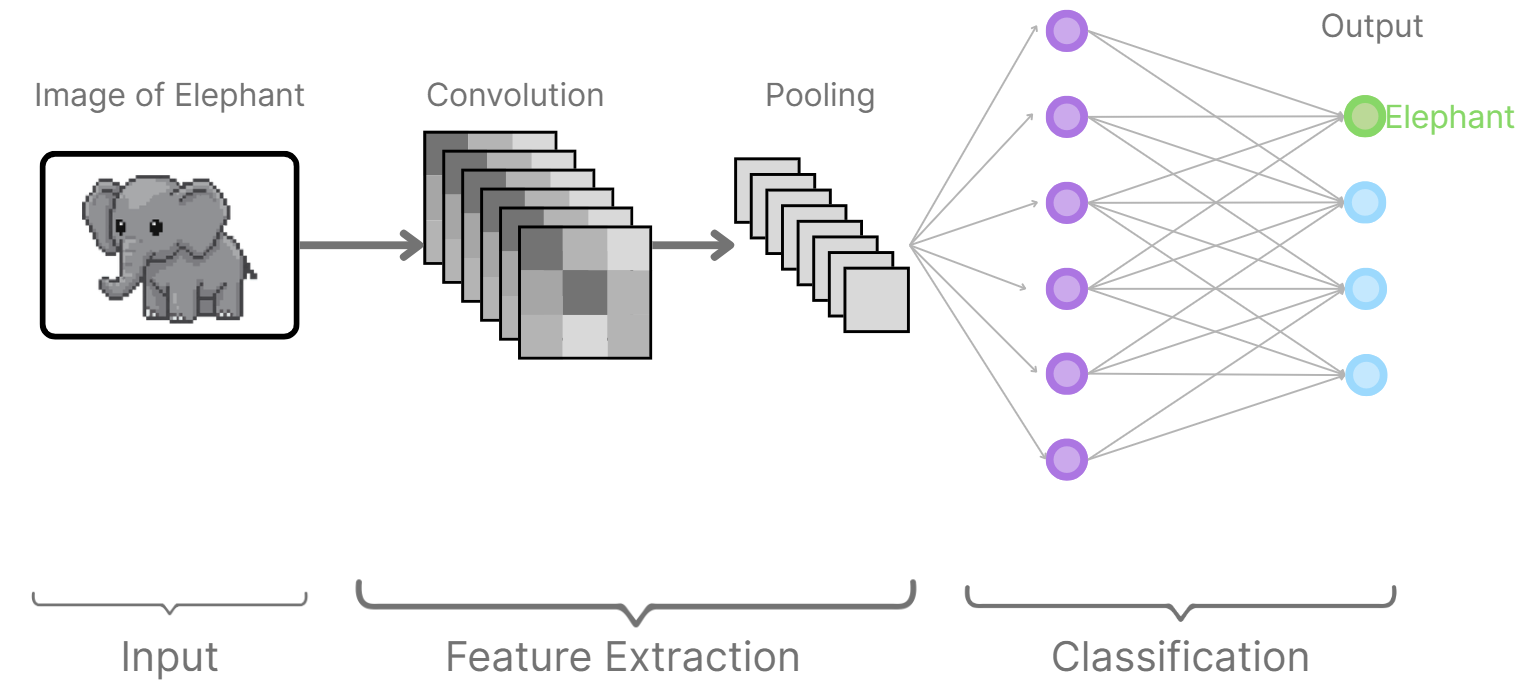
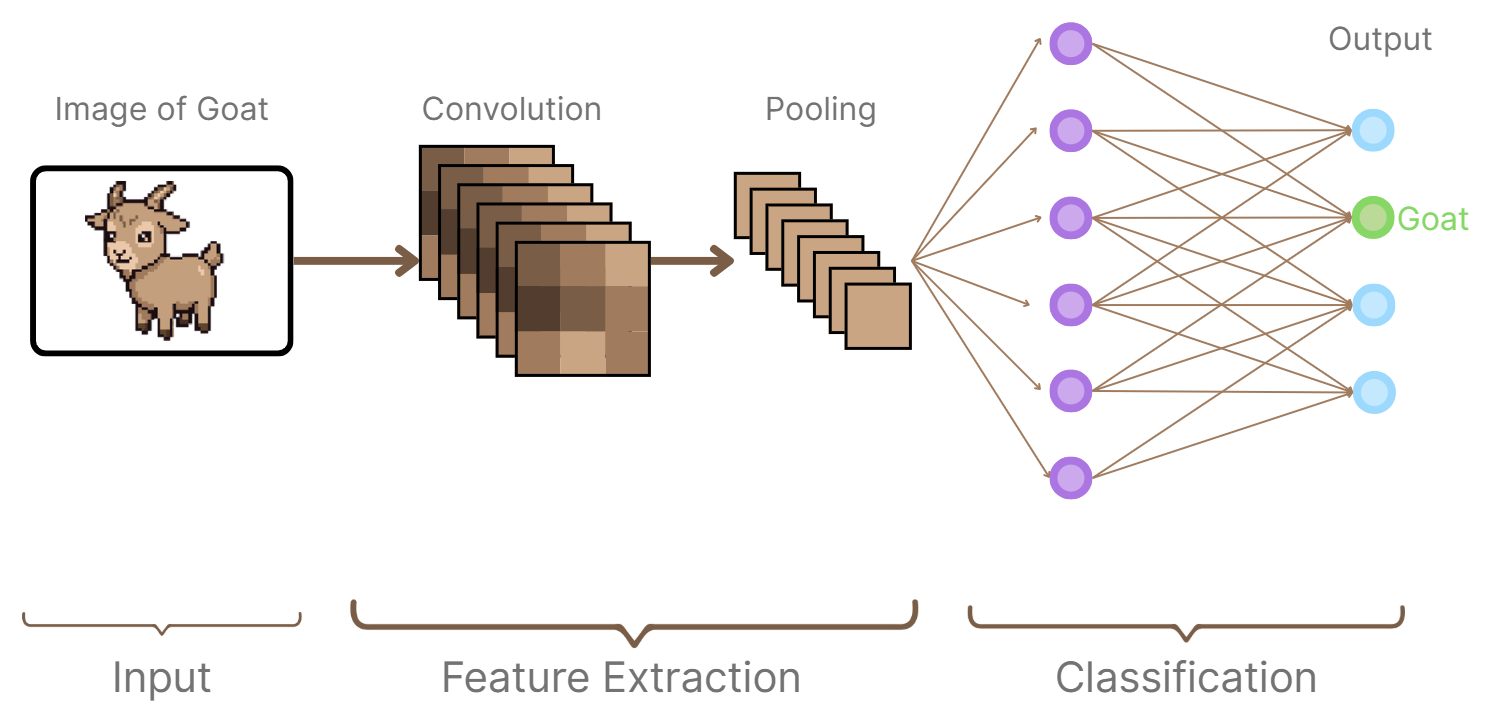
Convolutional Neural Network Diagrams (H.Y. using Canva)
▬▬▬▬▬▬
Recurrent Neural Networks (RNNs)
Recurrent neural networks specialise in processing sequential data, like text, speech, or time-series signals. As opposed to FNNs, RNNs have feedback connections so that
they can keep a kind of "memory" of what they have seen in the past. At every step, the network computes the new hidden state based on the current input and previous hidden state.
This allows the network to process sequences of any size and learn about dependencies between earlier and later items. But RNNs are troubled by long-term dependencies because
the memory fades over many steps, leading to issues like vanishing gradients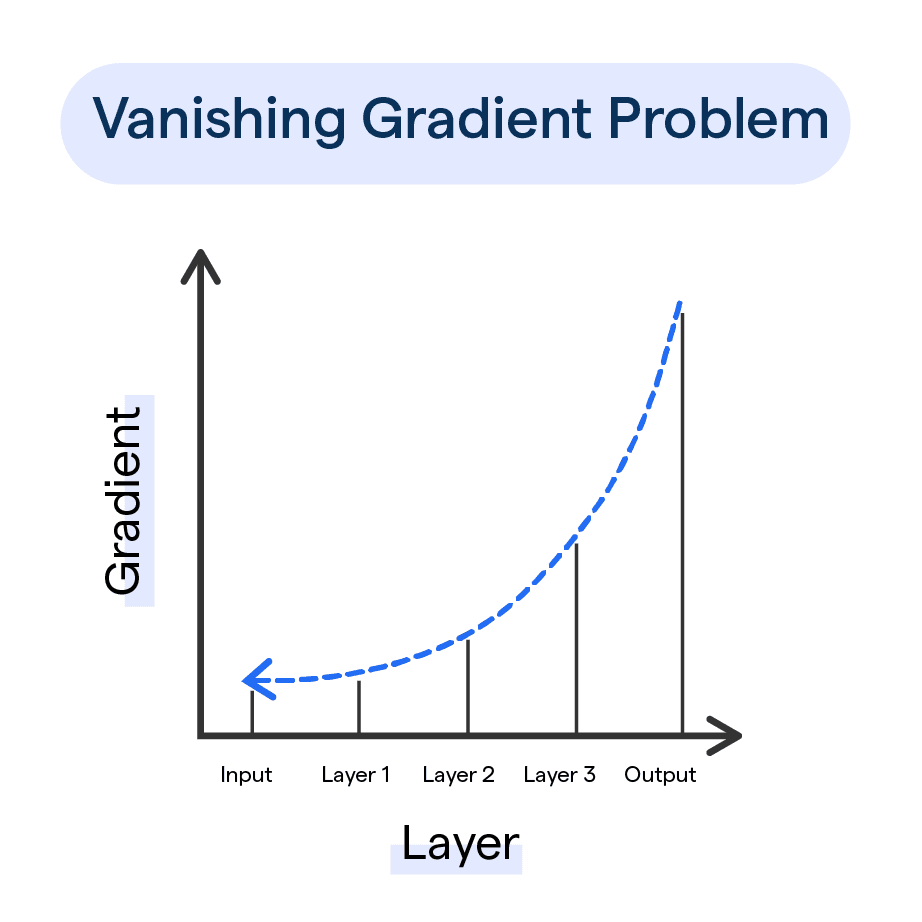
(BotPenguin, n.d.)
The vanishing gradient problem is when the weights and biases update very slowly when we use gradient descent. This means the early layers hardly change,
so the network has trouble learning deep patterns..
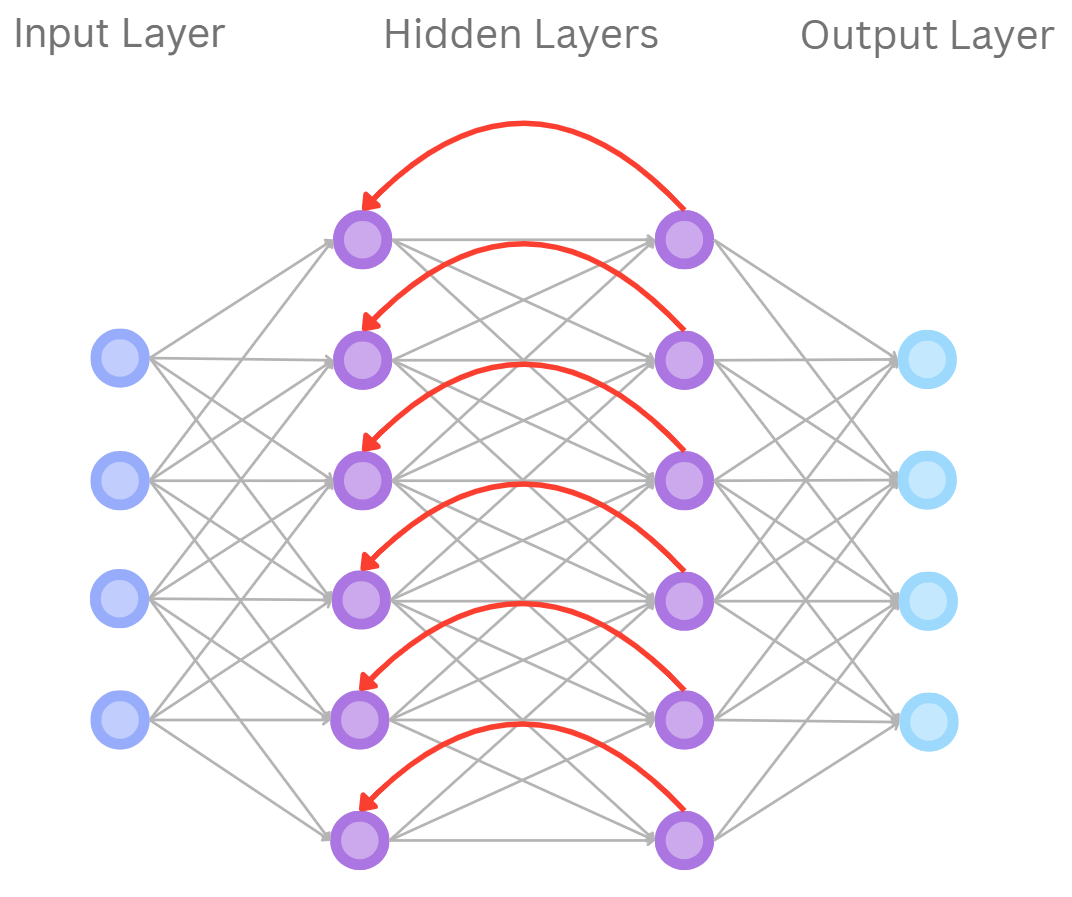
Recurrent Neural Network Diagram (H.Y. using Canva)
▬▬▬▬▬▬
Long Short-Term Memory Networks (LSTMs)
LSTMs are a more advanced form of RNNs that solve the problem of long-term memory. They possess a more complex cell structure with gates which control the information flow. The input gate calculates how much of the current input to remember, the forget gate calculates what to erase, and the output gate calculates what to send forward. This architecture allows LSTMs to remember for a lot longer than regular RNNs, which makes them extremely powerful at things like machine translation, speech recognition, and music composition.
In LSTMs, there are essentially 2 types of memory: the hidden state (\(h_t\)) and the cell state (\(C_t\)). The hidden state acts as "short-term" memory,
and only hidden layers very close to it can access this information. The cell state on the other hand is more like "long-term" memory, and it solves the vanishing gradient problem
(BotPenguin, n.d.)
The vanishing gradient problem is when the weights and biases update very slowly when we use gradient descent. This means the early layers hardly change, so the network has trouble learning deep patterns.
that normal RNNs have.
▬▬▬▬▬▬
At each step of the process, the LSTM has access to:
- The current input (say, a word or number in the sequence)
- The hidden state from the previous step (short-term info)
- The cell state (long-term memory)
With this, the LSTM first decides what to "forget". This is done by the forget gate which looks at the input as well as the previous hidden state and decides what parts of the old cell state to throw away.
For
example, “Forget the subject of the sentence if a new one has started.”
Then, the input gate decides what new info to add to the cell state (the long-term memory). So, in our example, it might be, “Add the new subject into memory”
Finally, the output gate decides what part of the updated cell state should influence the hidden state (the short-term output used right now).
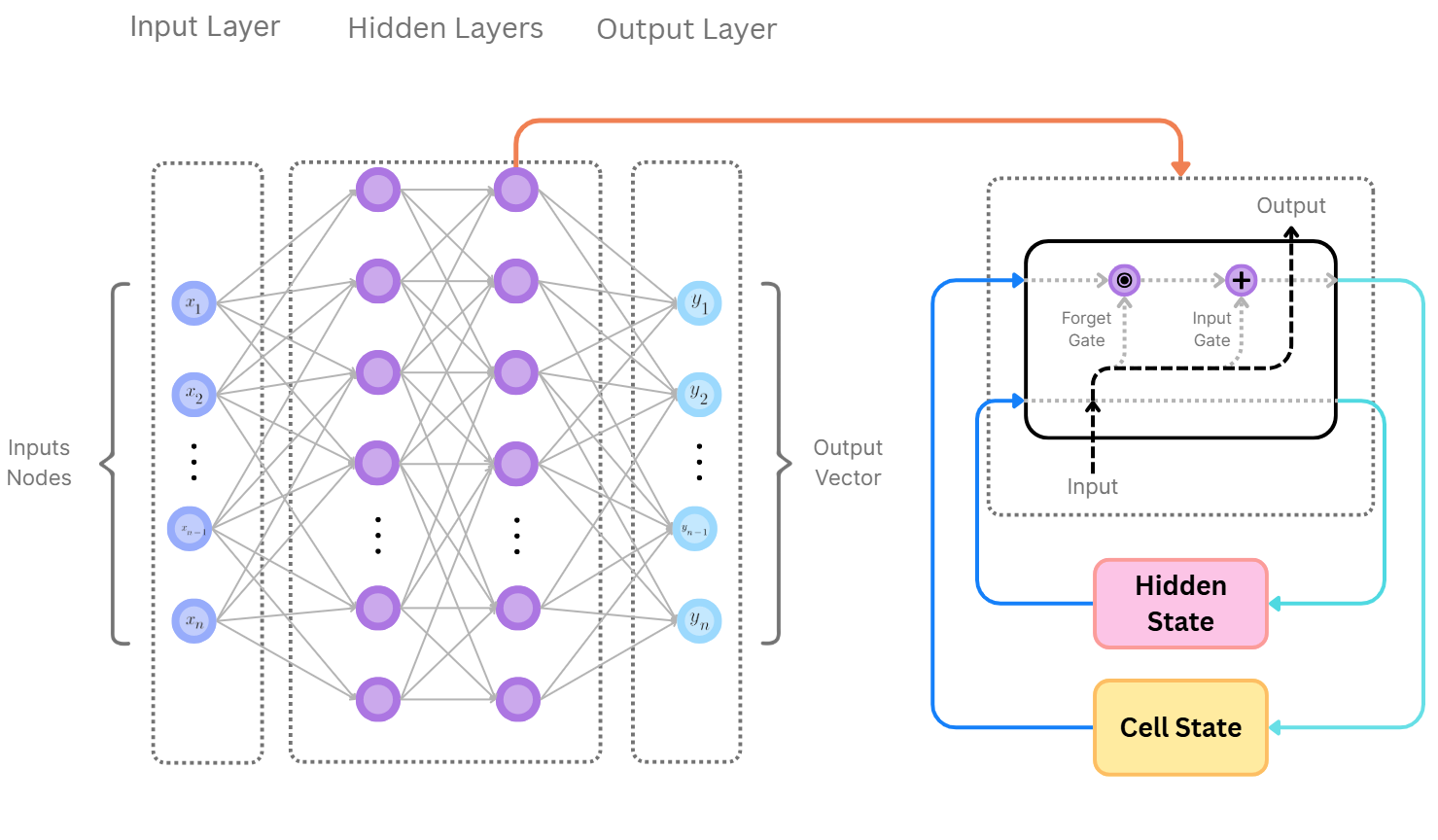
LSTM Diagram (H.Y. using Canva)
▬▬▬▬▬▬
Transformers
Transformers are a newer architecture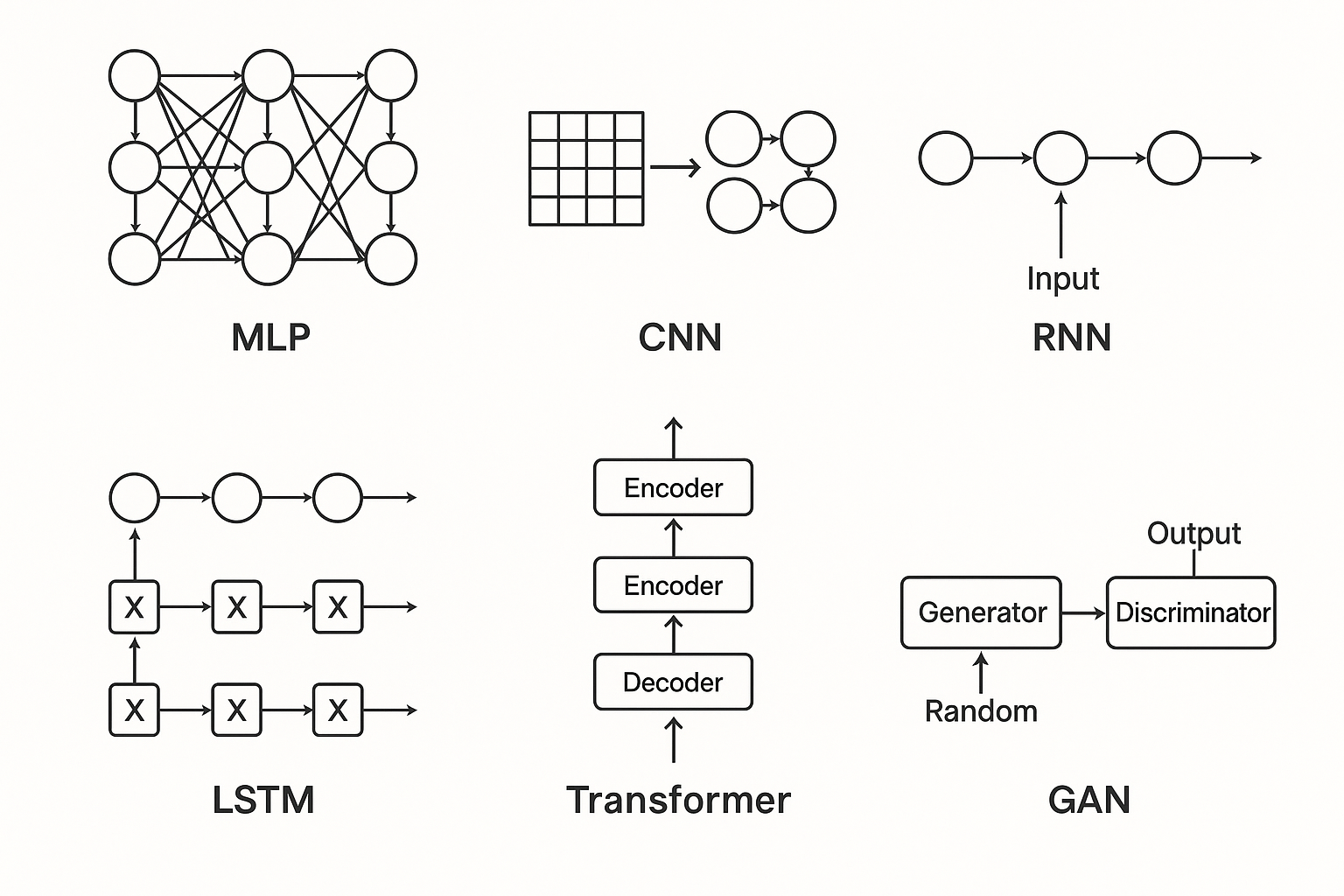
(Sora, 2025)
A neural network architecture is the specific arrangement of layers, neurons, and connections that defines how a
neural network processes and transforms input data to produce an output. that has now replaced RNNs and LSTMs on sequence modelling
tasksA sequence modeling task is one where the goal is to
predict, generate, or analyse data that comes in a specific order, like words in a sentence or frames in a video. These tasks require the model to capture
patterns and dependencies across the sequence to make accurate predictions.. Unlike RNNs that process one step in a sequence at a time, transformers
process the entire sequence at once and use self-attention layersA self-attention layer is a component of a transformer that lets each element in a sequence look at and weigh all the other elements to decide which
ones are most relevant. It computes attention scores that determine how much influence each element has on the others, allowing the network to capture relationships across the entire
sequence. This mechanism is key for understanding long-range dependencies efficiently. to figure out which parts of the input are most relevant to each other. This allows them to capture long-range
dependencies efficiently with residual connections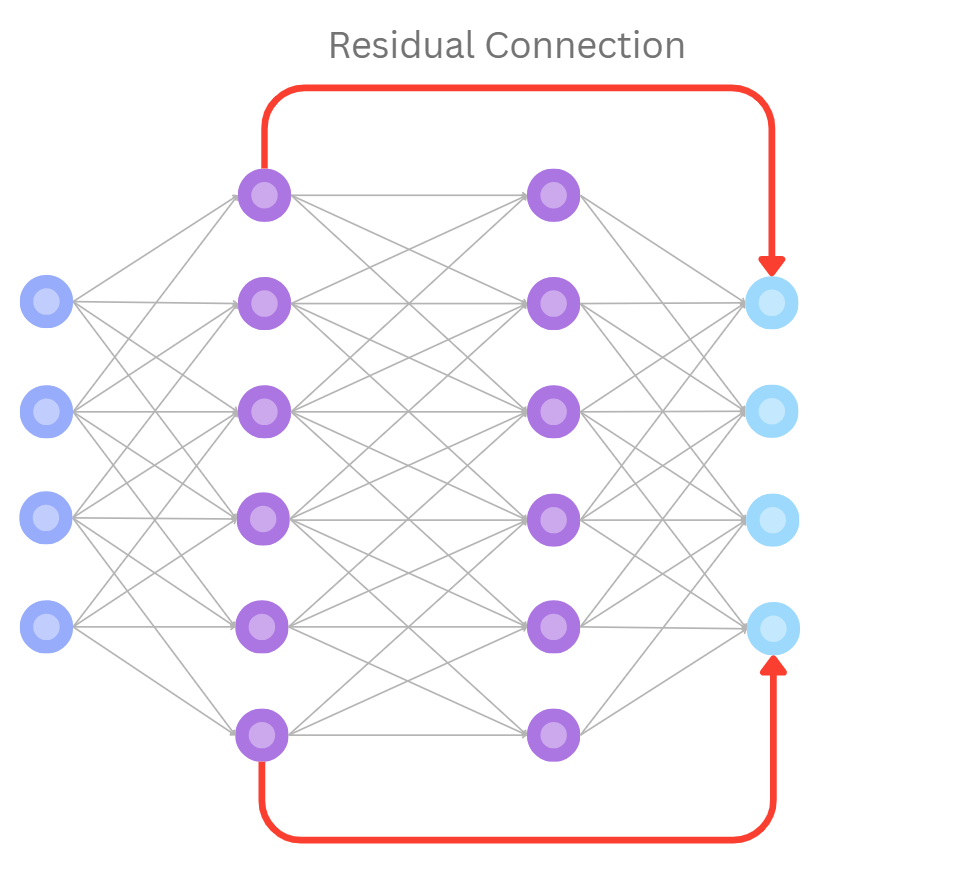
(H.Y., 2025)
A residual connection is a shortcut in a neural network that adds the input of a layer directly to its output, helping the network retain important information.
This makes training deeper networks more stable and efficient by preventing the signal from vanishing. and feedforward layers helping to blend and stabilise the information.
The key strength of transformers lies in something called “self-attention”, which enables the model to weight relationships between all elements in a sequence simultaneously.
For instance, in a sentence, it could know that "bank" is related to "river" in one context and to "money" in another, but positional encodings keep track of the order of words
since the model sees everything at once. By combining attention and parallel processing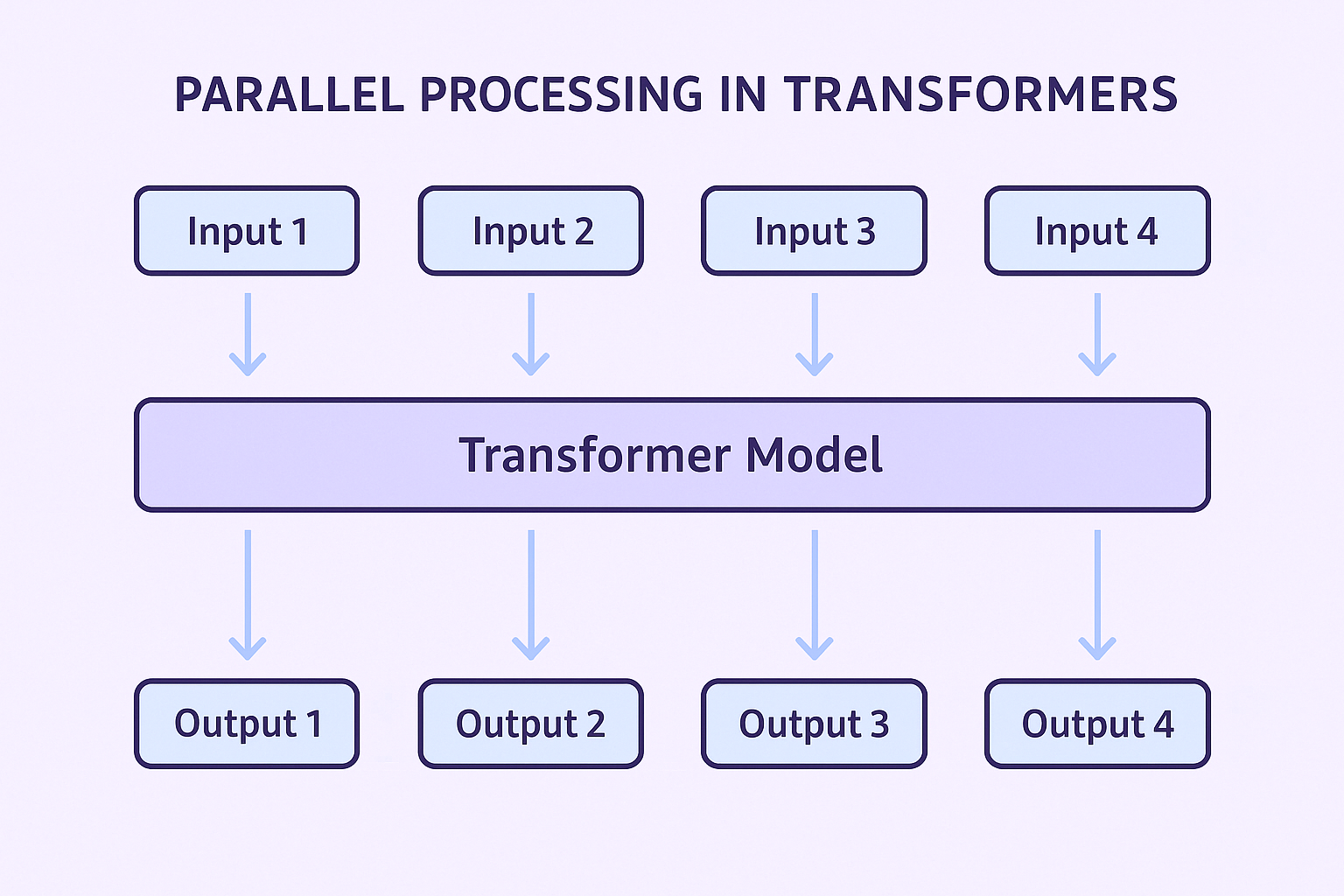
(Sora, 2025)
Parallel processing is when a model processes all elements of a sequence at the same time instead of one by one, allowing faster computation and better handling of
long-range dependencies., transformers excel particularly at translation, summarisation, and text generation tasks.
Although this seems vastly different to normal neural networks and despite all their complex architecture, transformers still remain neural networks at their core.
▬▬▬▬▬▬
Roughly, this is how a transformer works:
- 1. Input Embedding: The first step is to convert each element of the sequence (like a word in a sentence) into a vector of numbers, called an embedding. These embeddings capture semantic meaning. For example, “cat” and “dog” might have similar vectors because they’re both animals.
- 2. Positional Encoding: Because transformers don't process the sequence one bit at a time, they need something to tell them the position of the elements. This is why positional encodings are added to each embedding to give the network information about the position of each element (like a word) in the sequence.
- 3. Self-Attention: Then, each token in the sequence looks at every other token and decides how much attention to pay to them. For instance, in the sentence, "The cat sat on the mat", the token "sat" pays more attention to "cat" than to "mat" when constructing its representation. Mathematically, this is done by computing attention scores and combining the embeddings of other tokens based on those scores.
- 4. Feedforward Layer: This new representation of every token is then passed through a small neural network (feedforward layer) that combines information and detects more complex patterns.
- 5. Residual Connections: Then, the transformer adds residual connections
(H.Y., 2025)
A residual connection is a shortcut in a neural network that adds the input of a layer directly to its output, helping the network retain important information. This makes training deeper networks more stable and efficient by preventing the signal from vanishing. to stabilise training and normalise the output Normalising the output is the process of scaling a layer’s activations so they have a consistent mean and variance, which helps stabilise and speed up training. It prevents extreme values from dominating and allows deeper networks to learn more effectively.. This allows for learning of deeper relationships without losing important information. - 6. Stacking Layers: Steps 3–5 are then repeated a many many times in a stack of layers. Each layer refines the representation of the sequence a bit more, allowing the model to learn more abstract and long-range dependencies.
- 7. The Output Layer: Finally, the transformer produces an output for each token (for tasks like translation or text generation) or a summary representation (for tasks like classification). These outputs are then normally passed
through a special function like a softmax
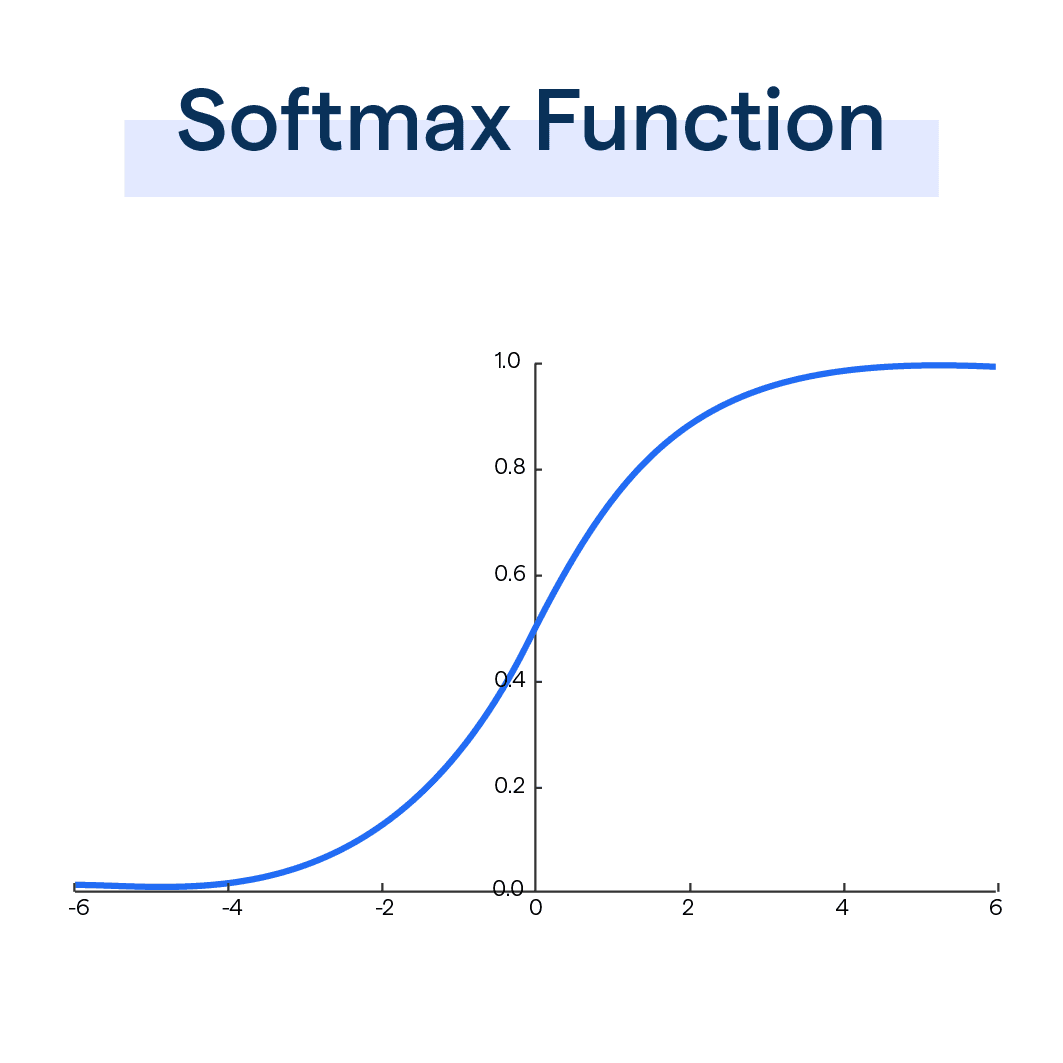
(BotPenguin, n.d.)
A softmax is a function that converts a vector of numbers into probabilities that sum to 1. It’s commonly used in the output layer of a neural network for classification tasks, so each output can be interpreted as the probability of a certian class. to produce probabilities or make decisions.
Transformer Diagram (H.Y. using Canva)
▬▬▬▬▬▬
Generative Adversarial Networks (GANs)
Generative adversarial networks (GANs) work quite differently from the other types of neural networks mentioned above. It consists of 2 competing models “fighting” one another: a generator and a discriminator. The generator tries to produce data (like artificial images) that are similar to real data, while the discriminator tries to figure out if data is real or fake. The more the process goes on, the more the generator gets better and better until it can produce highly realistic outputs. This means that GANs are usually used for generating things like images, videos, and music pieces.

GAN Diagram (H.Y. using Canva)
▬▬▬▬▬▬